我见过太多人把 claude code 当成“更会写代码的聊天框”,结果越用越乱。真正能把 claude code 跑稳的做法,是把它当成一个能被约束、能被检查、能被复盘的协作流程。下面这份笔记不是追求花哨技巧,而是把 claude code 用在日常开发里最管用的细节:场景边界、CLAUDE.md、工具调用、测试节奏,以及如何把 claude code 的输出变成团队可用的成果。
访问入口:chat.aimirror123.com 与 chat.write360.cn。
最后更新时间:2026-01-26

claude code 的目标边界:先写清楚“能做什么”
我最常见的错误不是提示词写得差,而是 claude code 根本不知道这次要解决哪一类问题。比如“优化性能”“修复 bug”这种说法太松,claude code 只能靠猜。更稳的做法是把目标写成可以检验的动作:改动范围、影响文件、验收方式。只要边界写清楚,claude code 的输出会立刻变得可控。
我会用两句就把边界定死:一是“只改某目录”,二是“输出必须附验证步骤”。这两句能让 claude code 从一开始就走在正确路线上。很多时候,claude code 不需要更聪明,只需要更明确。
claude code + CLAUDE.md:把上下文变成长期资产
claude code 最吃上下文。每次重复讲项目背景,既浪费时间也浪费 token。把“固定信息”写进 CLAUDE.md,是我认为最值得坚持的习惯。比如常用的脚本、代码风格、目录结构、测试命令、发布流程,这些都应该成为 claude code 每次启动就能读到的内容。1
我会把 CLAUDE.md 设计成“可复用的项目清单”,而不是散乱的说明文。内容不要贪多,但要实用,比如:常用脚本、代码风格、常见坑、必须避开的风险点。这样 claude code 不需要反复提问,就能直接进入执行状态。
# 项目规则
- 只改 src/ 与 scripts/
- 需要通过 npm run test:unit
- 禁止改动 public/
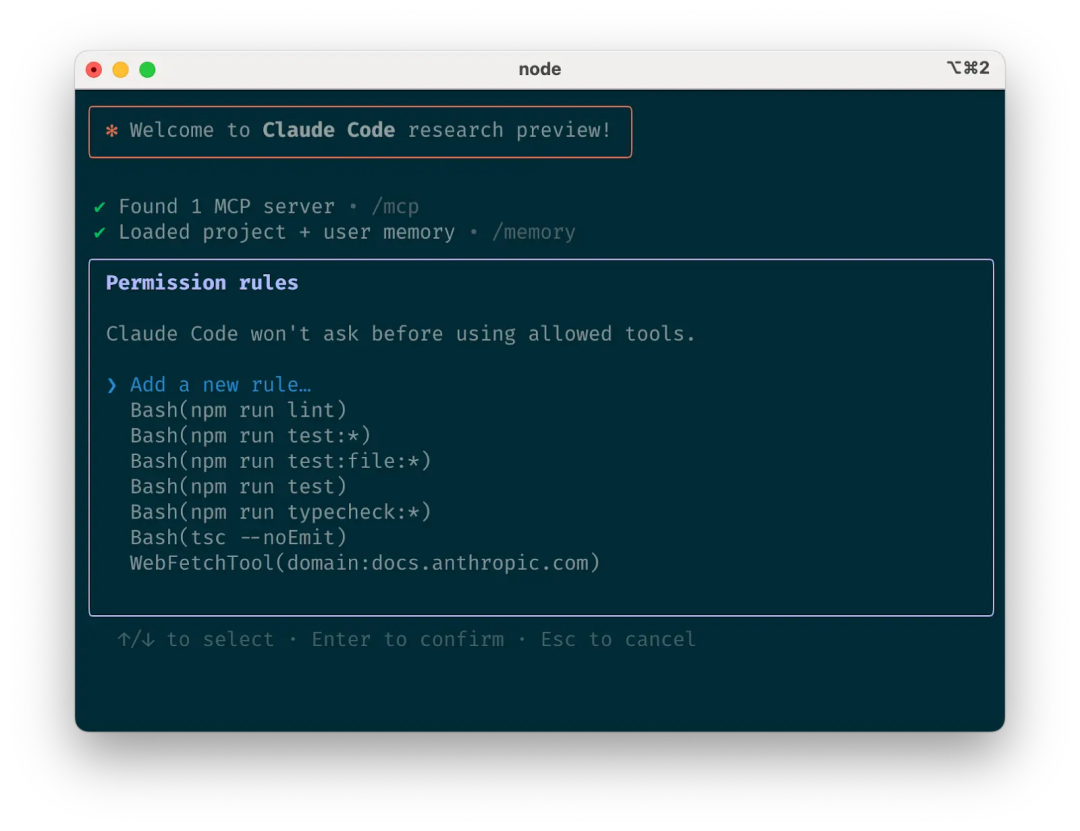
当团队协作时,把 CLAUDE.md 提交进仓库更稳。这样 claude code 在不同人手里表现会更一致,也更容易形成固定的交付标准。
claude code 的材料准备与上下文压缩
很多人觉得 claude code 读不懂项目,其实问题常出在材料准备。只要你把“必须看的文件”列清楚,把“暂时不用的目录”标出来,claude code 就能省下大量无用上下文。不要把全仓库扔给 claude code,反而会拖慢判断。
我会把输入分成两层:一层是必须阅读的核心文件,另一层是可选参考。比如核心文件 3 个、参考文件 5 个,这样 claude code 知道先抓主线,再补细节。哪怕是大型仓库,claude code 也能在有限材料里做出更稳定的判断。
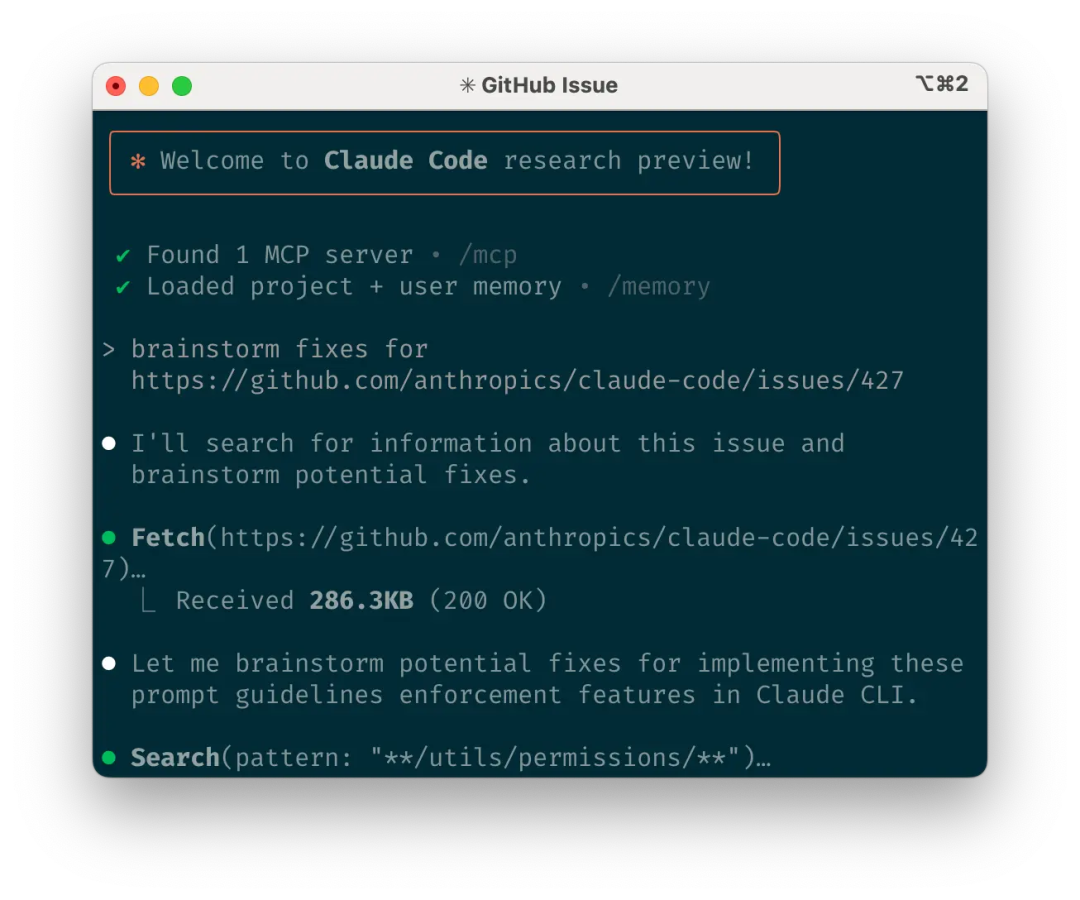
如果内容很长,我会让 claude code 先做“结构性摘要”,把模块和数据流写清楚,再决定下一步。这个动作看似慢,但能显著减少返工。真正让 claude code 变稳的,不是把上下文塞满,而是把上下文整理得有层次。
claude code 的提示词写法:少解释,多约束
我写 claude code 的提示词时,会把“约束”放在“解释”前面。原因很简单:claude code 会优先执行明确规则。你越早告诉它“不可以做什么”,它就越少绕路。输入格式、输出格式、不能改动的文件、必须保留的 API,这些都应该靠前。
下面是一个我常用的 claude code 提示词骨架,适合小改动任务,重点是约束清楚、输出可验证。
目标:修复 /src/payment 中的计算误差
范围:只改 /src/payment 与其测试
要求:输出 diff + 解释 + 运行哪些测试
限制:不得修改 public/ 与 assets/

这样写的 claude code 往往比“请帮我优化”好用得多。你会发现 claude code 的输出更像工程师的改动,而不是一段没有边界的建议。
claude code 的场景对照:用法要贴着问题走
很多人把 claude code 当成万能工具,结果遇到复杂任务就卡住。我的经验是按场景选用法:资料整理类、代码改动类、排障类、自动化类,每一类的提示词侧重点都不同。只要把场景说清楚,claude code 的判断会更稳。
下面这张对照表是我在团队里常用的参考,目的是让 claude code 的任务更具体,也更容易验收。你可以按自己的业务再细化。
| 场景 | claude code 的重点 | 建议输出 |
|---|---|---|
| 小范围修复 | 明确改动目录与验证命令 | diff + 测试结果 |
| 资料抽取 | 输入字段要固定 | 表格或清单 |
| 排障定位 | 先列日志与重现步骤 | 根因假设 + 验证方案 |
| 批量处理 | 成功/失败标记 | OK/FAIL + 摘要 |
| 这类对照表不是为了规范,而是为了提醒自己:claude code 不是靠“更长的提示词”变强,而是靠“更合适的输出形式”变稳。 |
claude code 的工具调用:让它“动手”而不是“猜测”
claude code 不是只会说,它可以读文件、跑命令、看差异。越早让 claude code 动手,越少出现“猜代码”的情况。我会在提示里明确允许它用 bash 或 git,并要求“先查看,再修改”。这能减少很多不必要的偏差。
举个例子,如果需要定位问题,我会让 claude code 先跑一次 rg,再把结果贴出来,再决定改哪一行。它一旦真的看到代码,输出质量会明显提升。
rg "payment" src/
git status -sb
还有一个细节:当 claude code 改了文件,我会要求它输出 git diff 的摘要或关键片段。这个动作能让审查更快,也能让 claude code 自己意识到改动是否过度。
claude code 的差异审查:先看改动,再谈结论
我很少直接接受 claude code 的结论,而是先看改动本身。让 claude code 先贴出改动,再给解释,这个顺序能降低“讲得通但改得不对”的风险。尤其是配置文件、依赖升级、权限相关的改动,必须先看 diff,再决定是否继续。
在提示里加一句“必须先输出 diff,再解释”,会让 claude code 的表达更谨慎。你甚至可以要求 claude code 给出“改动前后对比”的小表格,让审查更直观。这个习惯能大幅减少误改,也能让团队更放心把 claude code 的结果合进主干。
claude code 的测试节奏:小步验证比大改可靠
claude code 最怕的不是写错,而是写得太多。大改一旦失败,很难回退。我的习惯是把任务拆成“能被单元测试覆盖的小步”。每次改动只跑一个最关键的测试,确认通过后再继续。这样 claude code 的输出会稳定很多。
如果你已经有测试命令,就把它写进提示里,别等 claude code 自己猜。比如“只跑 npm run test:unit – payment”,这类指令能让 claude code 明确验证路径,也能节省运行成本。
我还会要求 claude code 在输出里写清楚“做了什么验证、没做什么验证”,避免结果看起来很漂亮却不可交付。
claude code 的合并策略:让改动可回退
合并策略决定了 claude code 的改动是否能被长期保留。我更倾向于小提交、可回退的节奏。claude code 每完成一段明确改动,就写一条清晰的提交信息,方便未来回滚。这样做会让 claude code 的输出更像工程师真实的工作流,也能减少后期排查的成本。
如果改动涉及多个模块,我会让 claude code 拆成多个提交,每个提交只解决一个问题。这个节奏能让审查更轻松,也能让项目历史更干净。你不需要 claude code 一次写完所有内容,你需要的是“每一步都能被理解”。
claude code 的自动化与无头模式:让流程能跑在 CI
当 claude code 从个人工具升级为团队流程时,无头模式会特别有用。它适合在 CI 或脚本里做批量处理,例如代码规范检查、文档抽取、日志分析。只要你把输入、输出与失败条件写清楚,claude code 就能在流水线里稳定运行。1
我的做法是给 claude code 明确“成功/失败标记”,比如要求输出 OK 或 FAIL,再由脚本接管下一步。这样即使 claude code 输出了很多内容,自动化也能抓住关键结果。
claude -p "检查 src/ 下是否存在未使用导入,完成后返回 OK 或 FAIL" --output-format stream-json
我还会在自动化脚本里限制 claude code 的输入长度,比如只传递最近一次改动的文件清单,而不是全量仓库。这样 claude code 的输出更快更稳定,也更容易定位错误。很多自动化失败不是功能问题,而是输入噪音太多。
claude code 的多实例协作:把复杂任务拆成几条线
单次会话里让 claude code 做太多事,效果往往会变差。我更喜欢开多个 claude code 会话,分别处理不同任务:一个负责重构、一个负责写测试、一个负责读日志。这样做的好处是上下文更干净,也不容易互相干扰。
如果项目是大仓库,我会配合 git worktree:不同目录开不同 claude code,彼此不打架。这样的工作方式更接近多人协作,也更容易控制风险。只要你把每个 claude code 的任务边界写清楚,结果会比单会话好很多。
claude code 的经验沉淀:把有效套路写成模板
真正省时间的不是一次性的提示词,而是可复用的模板。我会把跑得最稳的 claude code 提示词留进项目的文档里,附上适用范围和输入格式。这样下次有人接手时,不必再摸索,也能保持输出一致。
模板的价值在于节省沟通成本。比如“日志分析模板”“配置审计模板”“文档整理模板”,每个模板只解决一类问题,让 claude code 的工作更聚焦。你会发现 claude code 的效率是靠模板累积起来的,而不是靠一次次重新写提示。
claude code 的常见误区:不止是提示词问题
一个常见误区是把 claude code 当成“自动修复器”,看到问题就让它全量重写。这样很容易导致改动范围失控。更稳的做法是先让 claude code 做诊断,再让它动手改动,并把“必须保留的行为”写清楚。你会发现 claude code 不是做不到,而是需要更清晰的边界。
另一个误区是把 claude code 的输出当成最终答案。实际项目里,claude code 更像一位能加速工作的同事,你需要安排复核、验证和回滚路径。只要把这些环节固化,claude code 的结果就会越来越稳定,团队也更愿意长期使用。
claude code 的结果交付:让别人一眼看懂
最后一件事也是最容易被忽略的:claude code 的输出要“可交付”。我会让 claude code 在结果里写清楚三件事:改了哪些文件、为什么改、下一步建议做什么。哪怕只写三条,也比一大段泛泛解释更有用。
下面是我常用的交付模板,写进提示里能让 claude code 输出更统一。
输出格式:
1) 改动文件列表
2) 关键改动说明
3) 已执行的验证
4) 未覆盖的风险点
把这套模板固定下来后,claude code 的结果会更像真实工程交付,不会变成“只有作者看得懂”的草稿。很多时候,claude code 的价值不在于写得多,而在于写得可审、可查、可复用。
如果你正在把 claude code 引入团队,建议先从一个小任务开始,跑通“需求—改动—验证—交付”这条链路,再逐步扩大范围。只要节奏稳住,claude code 的优势会慢慢显现出来,而且会越来越省心。
我把这类 claude code 流程称为“可复盘路线图”,每次迭代都能看见提升。