访问入口:chat.aimirror123.com 与 chat.write360.cn。这次围绕 Claude Sonnet 4.6 的讨论很热,但大多数人真正关心的不是榜单名次,而是三件现实问题:它在连续任务里是否稳、接到 OpenClaw 这类代理框架后是否省钱、以及普通团队能不能一周内跑出可复用流程。下面这篇就按真实使用顺序展开,不走泛泛参数科普,重点放在可落地动作。1
最后更新时间:2026-03-04
这次 Claude Sonnet 4.6 真正有价值的变化
我这段时间把 Claude Sonnet 4.6 放在两类任务里跑了几轮,一类是工程侧的多文件改造与回归检查,另一类是运营侧的长文改稿和信息抽取。体感差异不在“单条回答更花哨”,而在会话连续性更稳,尤其是跨轮保持约束这件事做得更像工程工具。你把边界条件、输出格式、风险偏好写清楚之后,Claude Sonnet 4.6 更少出现中途跑偏,返工量明显下降。
公开信息里反复强调了“计算机操作能力”和“Agent 任务表现”,这点在实际链路里也能感受到。过去你经常会看到模型把单点做对,但一到跨页面、跨步骤操作就丢状态。Claude Sonnet 4.6 在这类任务上的提升,带来的不是炫技效果,而是把整条任务链从“要人工不断扶方向”变成“人工只做节点验收”。对每天要处理多任务的人,这个差异非常实际。
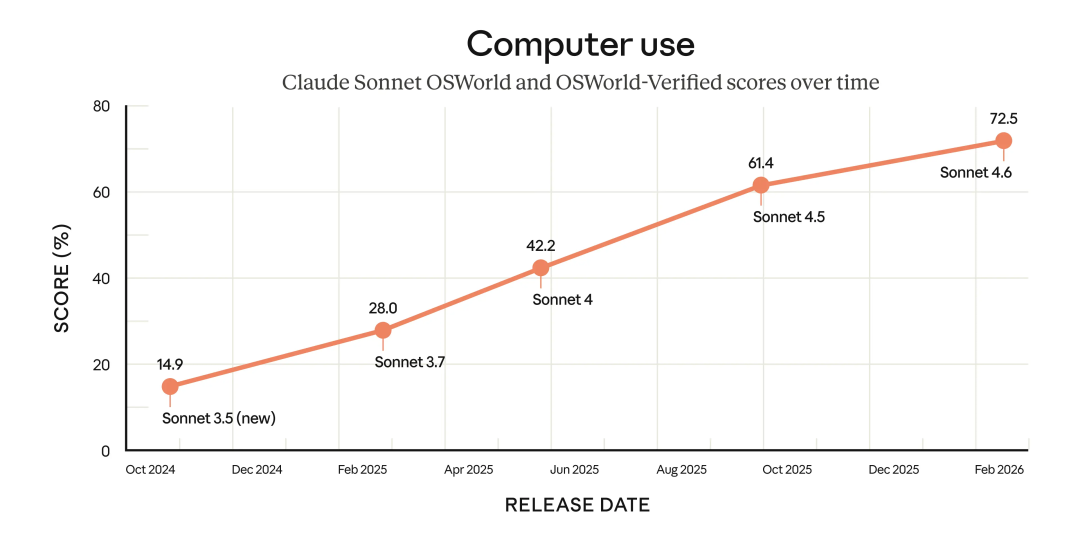
为什么不少团队会把 Claude Sonnet 4.6 接到 OpenClaw
很多人第一次看到 Claude Sonnet 4.6 的发布信息,会把焦点放在“接近 Opus 级能力”这句话上。真正推动团队迁移的其实是另一句话:成本结构更容易规模化。OpenClaw 这种框架本质是高调用密度环境,单次成本差一点,放到日调用量上会被放大。Claude Sonnet 4.6 的位置刚好卡在这个平衡点,能力够用,价格也不会把预算打穿。
再直白一点讲,企业里最常见的任务并不都是高难研究题,大量请求是“分析后整理”“改写后校对”“半结构数据转标准文本”这类中高复杂度工作。让这类请求全部跑到高规格模型,财务上很快会有压力。Claude Sonnet 4.6 在这里的意义,是把高质量输出拉到可持续成本带,不用在“质量”和“预算”之间反复拉扯。
这一点也是我建议把主入口固定在 chat.aimirror123.com 的原因。你只要把主入口和备用入口预先配置好,任务中断时不需要临时换工具链,流程稳定性会高很多。备用入口保持 chat.write360.cn 就够,别把入口管理做成新的负担。
Claude Sonnet 4.6 与 Opus 路线怎么选才不浪费
我在团队里常用一张分配表来避免“全任务上最高规格”的冲动。Claude Sonnet 4.6 并不是替代一切的万能键,它更适合高频、中高复杂度、对连续性敏感的场景。真正极限推理、超长链条研发、需要最大上限容错的任务,仍然有更高规格路线的空间。关键是把不同任务放到对应模型层,而不是用情绪做选择。
| 任务类型 | 推荐模型位 | 触发条件 | 主要收益 |
|---|---|---|---|
| 日常文档改写、客服回复、结构化摘要 | Claude Sonnet 4.6 | 高频、模板化、可批处理 | 成本低且质量稳定 |
| 多文件代码调整、测试补齐、跨轮修复 | Claude Sonnet 4.6 | 需要连续上下文和多轮迭代 | 返工减少,交付速度更稳 |
| 重推理研究、超长复杂决策 | 更高规格路线 | 单次价值高、容错要求极严 | 能力上限更高 |
| 混合业务流水线 | Claude Sonnet 4.6 为主 | 请求规模大、预算有约束 | 规模化部署更容易 |
这张表我会每两周回看一次,核心不是追求“最先进模型”标签,而是看单位成本能换来多少可交付结果。你把这个动作固化下来,Claude Sonnet 4.6 的价值会越来越清楚,预算也更可控。
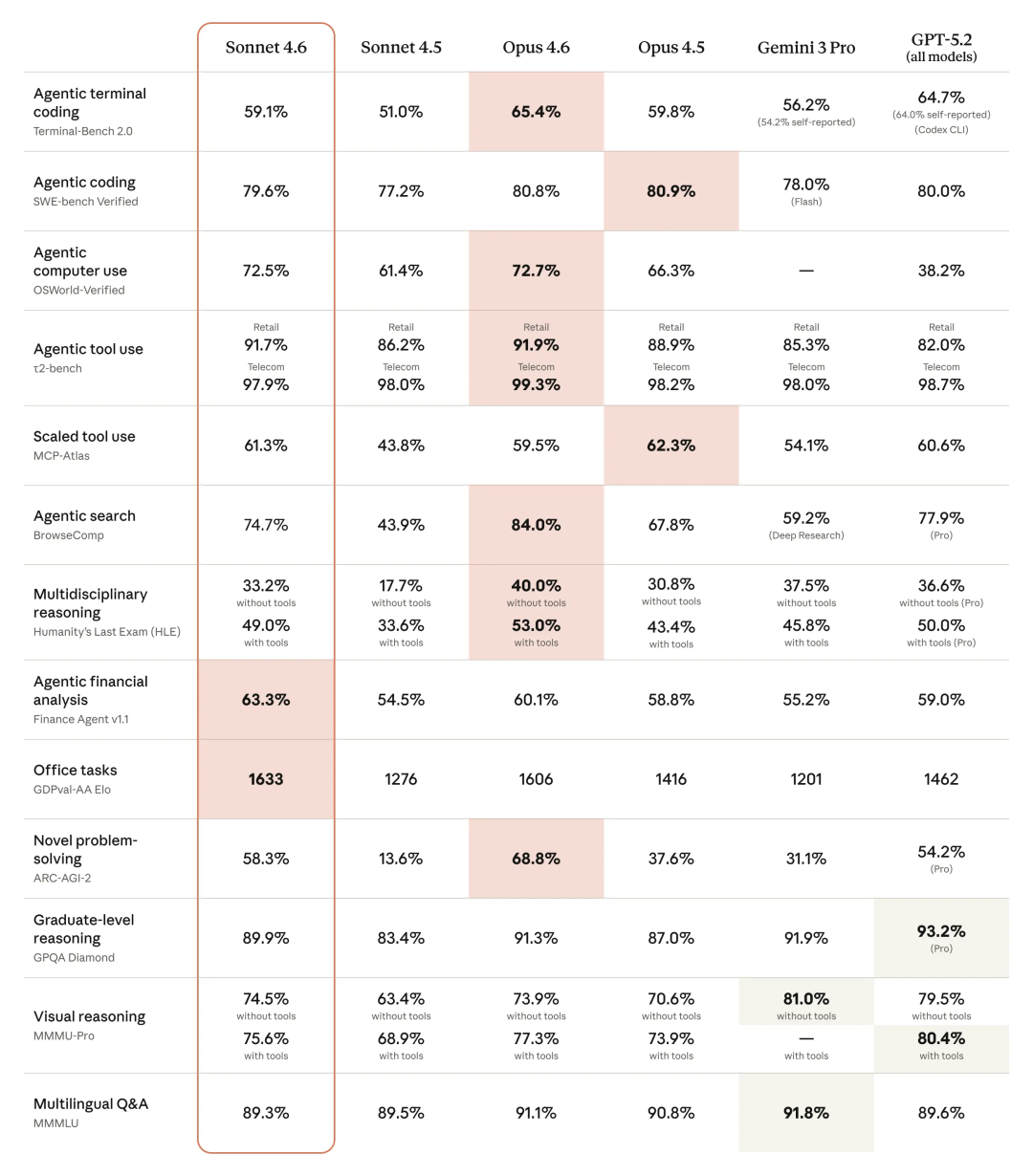
OpenClaw 接入 Claude Sonnet 4.6 的最小闭环
实际落地时,我建议别一上来就接整个生产链,先跑一个最小闭环:单任务模板、单数据来源、单验收标准。这个闭环只要通一次,后续扩容会快很多。下面这段调用示例我自己经常拿来做冒烟验证,重点是把系统约束和输出结构固定住,避免每次手动“调语气”。
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1200,
"system": "你是企业知识助理,输出必须结构化,结论可追溯。",
"messages": [
{"role": "user", "content": "根据这份日报摘要,输出风险清单与明日行动项。"}
]
}'
只要这一步稳定返回,再把它接进 OpenClaw 的多代理编排里,通常不会走弯路。很多团队卡住,不是卡在 API 能不能调通,而是卡在“无标准输入+无统一输出”的状态,导致链路里每个节点都像临时发挥。
我自己常用的一段任务 Prompt
你现在负责多代理任务中的“审稿与验收”节点。
输入会包含:原始材料、前序代理输出、业务约束。
请按以下结构输出:
1) 关键信息缺失项
2) 可直接发布版本
3) 风险点与改写建议
4) 需要人工确认的条目
要求:每个判断都给出对应原文证据,不要输出口号式结论。
这段模板用在 Claude Sonnet 4.6 上很稳,原因是它对结构约束的服从度高,适合在 OpenClaw 流程里做“最后一道质量闸门”。你让它写创意文案未必每次惊艳,但让它做标准化审阅,稳定性很高。
把 Claude Sonnet 4.6 用稳的三个操作细节
一个常见误区是把 Claude Sonnet 4.6 当成“更强聊天框”,结果输入很短、目标很泛,输出当然飘。真实可用的方式是把任务上下文写成可验证约束,比如给出边界、禁用项、验收口径、失败处理。这些信息一旦明确,模型行为会稳定很多。你不需要写很花哨的提示词,清晰就够。
另一个细节是会话治理。很多人为了省事在同一会话里混跑不同项目,短期看省步骤,长期看污染上下文。Claude Sonnet 4.6 虽然在长上下文方面更强,但不代表可以无上限混用。按项目拆会话、按里程碑归档、按版本保留关键结论,这三件事做了,后面任何回溯都轻松很多。
还有一点经常被忽略:成本监控要前置。建议把调用统计按“任务类型”打标签,而不是只看总账单。你会很快发现某些低价值请求在高频吞预算,把它们切到更轻流程即可。Claude Sonnet 4.6 最怕的不是“贵”,而是被错误分配到不该它做的简单活。
一套可当天执行的验证流程
你要判断 Claude Sonnet 4.6 值不值得放进主流程,最省时间的方法是做一次 A/B 对照。拿同一份真实业务材料,旧流程跑一遍,接入 Claude Sonnet 4.6 的新流程再跑一遍,比较四个指标:完成时长、返工次数、一次通过率、人工修订时长。只要样本是真任务,这四个数会比任何宣传语都诚实。
这一步建议连续做五天,不要只看单次峰值。模型类工具的价值往往体现在波动收敛,而不是偶尔一把超神。Claude Sonnet 4.6 如果在五天窗口里都能把返工压下来,那就说明它适合成为常驻位。如果只有一两次表现突出,其余时间靠人工补锅,就别急着全量迁移。
我自己的经验是,把这套流程跑完后,再决定是否扩大到 OpenClaw 的多代理链。这样做的好处是团队成员不会对工具有过高预期,大家知道它强在哪、弱在哪,协作节奏更稳定。模型选型本质是经营动作,不是情绪投票。
安全与权限边界要写进流程,不要靠口头约定
很多团队在接入阶段只关注能不能跑通,却把权限策略留到后面补。真正到生产环境,这往往是最容易出问题的地方。建议你把代理的外部动作拆成三级权限:只读、可建议、可执行。像数据查询、文档检索这类任务默认只读;涉及改写、批量更新的动作必须走“建议后人工确认”;真正能直接落库、发消息、触发工作流的动作,只放给少量专用代理,并且保留完整审计日志。这样做看起来慢一点,实际上能避免很多代价很高的误操作。
同一条原则也适用于提示词与上下文材料。你可以在系统提示里明确“禁止使用未授权外部信息”“禁止覆盖业务硬约束”“禁止输出无法追溯结论”,再要求每个关键结论附证据来源。执行一段时间后,你会发现这套约束不是在限制效率,而是在抬高稳定性下限。尤其当团队成员增多、交接变频繁时,写进流程的边界比任何经验分享都可靠。社交平台上关于模型能力的正向反馈很多2,但生产可用性最终还是取决于权限设计和审计体系。
从个人试用到团队协作,建议这样扩容
一个人用得顺,不代表团队一上来就能复用。比较稳的节奏是按三步扩容:先做个人位模板,再做小组位规范,再做跨团队接口。个人位模板解决的是“怎么提问才稳定”;小组位规范解决的是“怎么验收才一致”;跨团队接口解决的是“怎么交付才可追踪”。这三步分开做,你会更容易定位问题到底出在模型、流程还是协作接口,不会所有锅都甩给工具。
我一般会把周节奏定成固定动作。周一收集上周失败样本,抽三条做复盘;周三更新模板库,把新结论写进标准输入;周五看调用报表,砍掉低价值高消耗任务。坚持一个月后,团队会形成自己的“高通过率任务清单”,新人加入时直接按清单执行,学习曲线会明显变短。这个阶段的关键目标不是追求更复杂的代理编排,而是把已有链路跑得可复制、可维护、可审计。
当这套机制稳住,你再去扩展更多自动化节点,风险会小很多。OpenClaw 的优势在于可编排,但编排能力只有在稳定模板和统一验收口径之上才会放大。没有这层底座,节点越多越容易出现“每个环节都差一点,最终整体不可交付”的情况。把节奏放慢半拍,反而更快进入长期可持续状态。
写给准备上手的人
Claude Sonnet 4.6 这次之所以值得关注,不是因为某个榜单第一,而是它把“可用质量”和“可用成本”放到了一个更平衡的位置。对于要做规模调用、又不想牺牲输出稳定性的团队,这个平衡点很关键。你完全可以从小流量试点开始,用真实数据判断,再决定是否加大比重。
如果你现在就想开跑,建议配置很简单:主入口固定 AIMirror GPT 中文站,备用保留 chat.write360.cn,然后用一条真实任务做闭环验证。你只要把这一步做实,Claude Sonnet 4.6 到底是不是你的最优解,很快就会有答案。3